The development of the WoKaS database followed three steps: (i) identification of karst spring locations across the globe; (ii) sourcing for discharge observations of the identified springs; and (iii) evaluation of collected datasets, which included technical validation and quality assessment. The workflow of these steps is illustrated in Fig. 1.
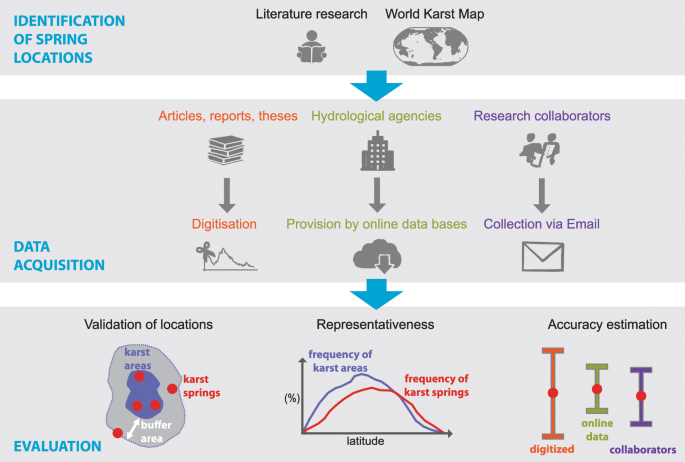
Workflow of the karst spring discharge observation database development.
Identifying karst spring locations
Firstly, we assembled the list of karst springs in countries with carbonate outcrops identified from the World Karst Aquifer Map4,19. For each country with carbonate outcrops, we performed an extensive literature search with a set of keywords consisting of: (1) country’s name; (2) karst; (3) spring; and (4) hydrology. From all the identified materials (articles, conference proceedings, reports, theses, news bulletins, books), we extracted karst spring names, location coordinates, elevation as well as land cover, catchment area (km2), defined as the topographic boundary within which the spring is located, recharge area (km2), defined as the area contributing to the recharge of the aquifer drained by the spring, and factors influencing discharge if such information were available. Several spring locations were also collected from WOKAM, which provides a list of relevant karst springs for each country, and from reviewing national databases.
Data acquisition
Time series of karst spring discharge observations were collected from three sources: (1) published data including scientific articles, reports and theses; (2) project partners and collaborators; and (3) public databases of national hydrological services. For each source, the method for data extraction, collection and gathering were different.
Published articles, reports and theses
A web search routine protocol was developed to look-up all publications in karst and non-karst hydrology containing karst spring hydrographs. Firstly, karst spring hydrographs of identified locations (see previous subsection) were searched in published journal articles. The keyword “hydrograph” was added to the set of keywords used in location identification (country’s name, karst, spring and hydrology). Occasionally, the country’s name was substituted with the spring’s name for a more specific web search. The search was further extended to published reports from NGOs, government agencies and PhD theses. The web search protocols for karst spring hydrographs and location identification were similar, hence, the two processes were usually run concurrently.
To extract the spring discharge observations from the published articles, theses and reports, we used WebPlotDigitizer (https://github.com/ankitrohatgi/WebPlotDigitizer). WebPlotDigitizer is an open source, web-based, semi-automatic digitization tool developed with HTML5 that works on most common web browsers. The hydrographs were cut out from the original publications, saved as image or pdf files and imported to WebPlotDigitizer. The raw discharge values for the total duration of the observation period were then extracted. Python codes for daily time step interpolation were used to post-process the extracted raw values.
Spring discharge observation time step are not usually stated in publications. Therefore, when the temporal resolution of the observation was unknown, the interpolation time step used was irregular and dependent on the resolution of the extracted figure: plot quality, number of plotted variables, and length or duration of the hydrograph. For instance, hydrographs that covered longer time periods only show seasonal and annual events, hence, a discharge variability could only be captured on monthly time steps. Whereas, if the observation period was shorter, individual events could be identified and discharge values could be extracted on a daily temporal resolution.
Research partners and collaborators
Additional data were acquired through the karst research community. Calls for data contribution were made at conferences, through social media platforms (Twitter and Facebook) and emails soliciting data support for the database to various research commissions, institutes, working groups and researchers with relevant datasets.
Hydrological agencies
A large number of karst spring discharge observations were obtained from national hydrological services that provide online access to their datasets. In total, we collected discharge datasets from ten national databases mainly in Europe and the United States of America (Table 1). Most of this data is in the public domain or published under the creative commons (CC-BY) license and could be directly combined with the data obtained from other sources (see above). Data from databases (Banque Hydro, eHYD, LUBW and NRFA) that do not provide their discharge data under the open data or CC-BY license are made available only as annual averages in the data repository23. To access this data at daily resolution, we provide an automatic download routine written with R, which extracts the karst spring discharge time series from the databases’ webpages directly. In addition, the download procedure updates the spring discharge time series of all databases in case new observations were added after publication of the WoKaS database (see following subsection).
Source: Resources - nature.com
