Predictors of viral sharing
We fitted a model designed to partition the contribution of species-level effects and pairwise similarity measures to mammalian viral sharing probability. We used a published database of 1920 mammal–virus associations (excluding humans) as a training dataset5. These data included 591 wild mammal species, equalling 174,345 pairwise host species combinations, with 6.4% connectance—that is, 6.4% of species pairs shared at least one virus. We used a generalised additive mixed model (GAMM) framework, including a species-level effect in our model as a multi-membership random effect, capturing variation in each species’ connectedness and underlying viral diversity (see Methods). Overall, our model accounted for 44.8% of the total deviance in pairwise viral sharing, with 51.1% of this explained deviance attributable to the identities of the species involved (i.e., the species-level effect). Our model structure was effective at controlling for species-level variation in our dataset: when we simulated networks using just these parameters, species’ predicted centralities were very close to their observed centrality (Supplementary Fig. 1). These results suggest that ~50% of the dyadic structure of observed viral sharing networks (in contrast to the true underlying network) is determined by uneven sampling and concentration on specific host species, and the remainder by macroecological processes.
As expected, increasing host phylogenetic similarity and geographic overlap were associated with increased probability of viral sharing across mammals, together accounting for the remaining 49% of explained model deviance (Fig. 1a–c). Geography, phylogeny, and their interaction all showed strong nonlinear effects, with geographic overlap in particular driving a rapid increase in viral sharing that began at ~0–5% range overlap values, peaked at 50% overlap values, and then levelled off (Fig. 1b). This effect closely mirrors previous observations of strong, nonlinear effects of geographic and phylogenetic similarity determining within-order viral sharing14,16,17,18,19. Curiously, we observed a downturn in sharing probability as closely related species exceeded 50% geographic overlap (Fig. 1b). However, this effect is of relatively limited importance in the context of our dataset: 93% of mammal pairs had less than 5% spatial overlap, while less than 0.5% had >50% overlap (Fig. 1b, d). The sparseness of data at this end of the distribution may also expose this effect to more unaccounted-for sampling biases, though some mechanistic explanations, such as apparent competition22, are plausible. The great majority (86%) of mammal pairs in our dataset did not overlap geographically and rarely shared viruses unless phylogenetic similarity exceeded ~0.5 (Fig. 1a). This phylogenetic distance corresponds roughly to order-level similarity; that is, if two species did not overlap in space, it was highly unlikely that they shared a virus unless they were within the same taxonomic order (8% of pairs). Notably, phylogenetic similarity accounted for more than twice as much model deviance as did spatial overlap (33.8% vs 14.4%). The greater importance of phylogeny relative to geography contrasts with previous analyses concerning viral sharing in primates19 and ungulates16, likely reflecting the wider phylogenetic range of hosts considered here. This finding supports the important role of mammalian evolutionary history in shaping contemporary patterns of viral sharing and diversity5,23.
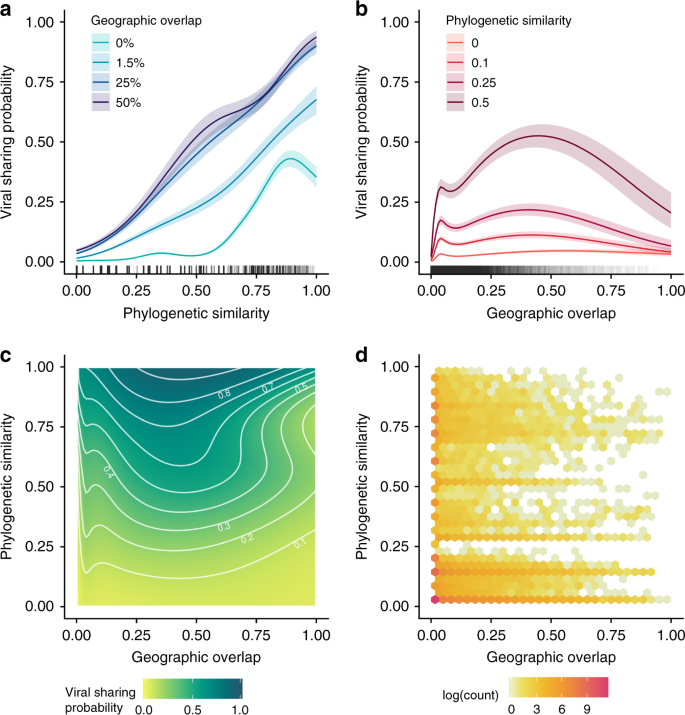
a Predicted viral sharing probability increases with increasing phylogenetic relatedness; the different coloured lines represent different geographic overlap values. b Predicted viral sharing probability increases with increasing geographic overlap; the different coloured lines represent different phylogenetic relatedness values. c The geographic overlap:phylogenetic similarity interaction surface, where the darker colours represent increased probability of viral sharing. White contour lines denote 10% increments of sharing probability. Labels have been removed from some contours to avoid overplotting. d Hexagonal bin chart displaying the data distribution, which was highly aggregated at low values of phylogenetic similarity and especially of geographic overlap.
In contrast to geography and phylogeny, minimum citation count and domestication status accounted for a vanishingly small amount of the deviance in viral sharing probability (0.2% and 0.1%, respectively) even though they have important effects on observed viral diversity in this dataset5. Their impacts on viral sharing may have been largely accounted for by the species-level random effects.
Our use of a pan-mammalian viral sharing dataset with a large sample size allowed us to investigate how geographic overlap and phylogenetic similarity affect viral sharing across different viral subgroups. These subgroups included RNA viruses, vector-borne RNA viruses, non-vector-borne RNA viruses, and DNA viruses. The importance of geographic overlap varied widely across all groups of viruses (Supplementary Fig. 2 and Supplementary Table 1), while the influence of host phylogenetic relatedness was more consistent (Supplementary Fig. 3 and Supplementary Table 1). Generally, host phylogeny was more important in determining sharing of DNA viruses than it was for RNA viruses, while space sharing was more important for vector-borne RNA viruses, and less so for non-vector-borne RNA viruses. These results likely reflect important aspects of viral ecology, transmission, and evolution. For example, RNA viruses are fast-evolving, allowing them to more quickly adapt to novel hosts, such that phylogenetic distances are less important in determining viral sharing patterns24. Conversely, DNA viruses are more evolutionarily constrained, with an evolutionary rate typically <1% that of RNA viruses25, such that phylogenetic distance between hosts presents a more significant obstacle for sharing of DNA viruses. The profound importance of geographic overlap in shaping the viral sharing network for vector-borne RNA viruses (Supplementary Fig. 3) likely emerges from the geographic distributions and ecological constraints placed on vectors, lending further support to efforts to model the global spread of arboviruses by predicting changes in their vectors’ distributions and ecological niches26,27. Generally, the fact that viral sharing across different viral subgroups was predicted by different macroecological relationships suggest they should be examined separately in future analyses where possible.
Predicting pan-mammalian viral sharing
Previous trait-based approaches used to model viral sharing and reservoir hosts have been hindered by incomplete and inconsistent characterisation of traits central to those modelling efforts. In contrast, spatial distributions and phylogenetic data are readily available and uniformly quantified for the vast majority of mammals and, as we have shown, are reliable predictors of viral sharing (>20% of total deviance). Thus, we used our GAMM estimates to predict unobserved global viral sharing patterns across 8.8 million mammal–mammal pairs using a database of geographic distributions28 and a recent mammalian supertree29 (see Methods). The predicted network included 4196 (non-human) Eutherian mammals with available data, 591 of which were recorded with viral associations in our training data. We calculated each species’ predicted degree centrality, as a simple and interpretable network-derived measure of viral sharing: that is, the number of other mammal species a given mammal species is expected to share at least one virus with. We identified geographic and taxonomic trends in degree centrality, validated our predicted sharing network using an external dataset, and simulated reservoir identification to assess host predictability for focal viruses (see Methods). For a visual representation of the predicted viral sharing matrix, see Supplementary Fig. 4.
We confirmed that our modelled network recapitulated expected patterns of viral sharing using the Enhanced Infectious Diseases Database (EID2) as an external dataset30. This dataset was constructed by mining web-based sequence data to identify host-pathogen associations, many of which are mammal–virus interactions30. Pairs of species that share viruses in EID2, but which were not in our training dataset (see Methods), had a much higher mean sharing probability in our predicted network (20% vs 5%; Fig. 2a). In addition, more central species in the predicted network were more likely to have been observed with a virus, whether zoonotic (Fig. 2b) or non-zoonotic (Fig. 2c), implying that the predicted network accurately captured realised the potential for viral sharing and zoonotic spillover. This finding concurs with similar work in primates that demonstrated that high centrality in primate–parasite networks is associated with carriage of zoonoses31. We corroborate these findings considering all mammal–mammal viral sharing links, not just zoonotic links, and show that for each mammalian order, species with higher degree centrality in our predicted network are more likely to have been observed with viruses in the EID2 dataset (Fig. 2c and Supplementary Fig. 5). Species with higher centrality in the global viral sharing network are likely more important for viral sharing overall, and thus have also been more likely to be observed with a (zoonotic) virus. Species that are more central in our predicted network could therefore be prioritised for zoonotic surveillance or sampling in the event of viral outbreaks with unknown mammalian origins. Given that mammal diversity predicts patterns of livestock disease32 and zoonoses33, the geographic patterns of degree centrality predicted here (Fig. 3 and Supplementary Fig. 6; see below) could also be used as a coarse predictor of viral disease risk to livestock and human health, providing additional insights that emerge from the joint, nonlinear effects of geography and phylogeny as opposed to the examination of their effects in isolation. Similarly, where there is limited knowledge of mammalian host range for newly-discovered viruses, our modelled network can be used to prioritise the sampling of additional species for viral surveillance.
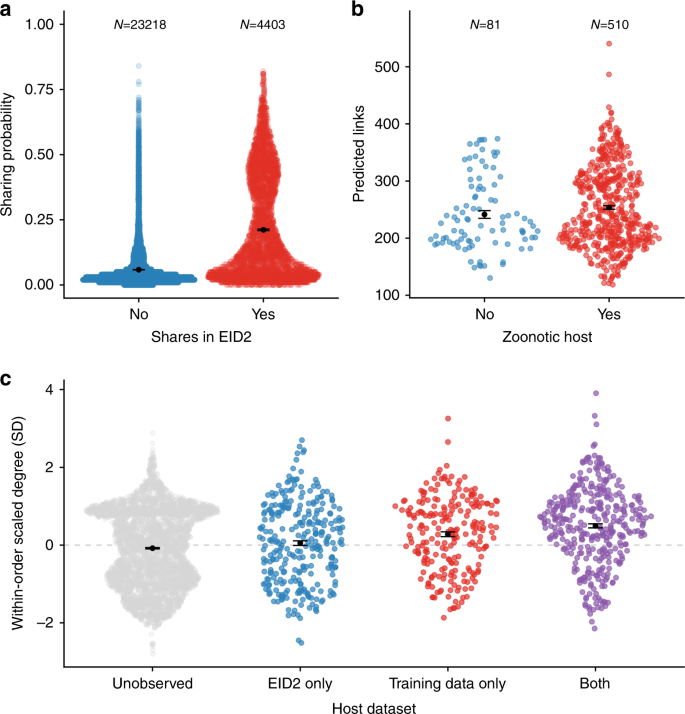
In all figures, points are jittered along the x-axis according to a density function; the black points and associated error bars are means ± standard errors. a Species pairs with higher predicted viral sharing probability from our model were more likely to be observed sharing a virus in the independent EID2 dataset. This comparison excludes species pairs that were also present in our training data. b Species that hosted a zoonotic virus in our dataset had more viral sharing links in the predicted all-mammal network than those without zoonotic viruses. c Species that had never been observed with a virus have fewer links in the predicted network than species that were known to host viruses in the EID2 dataset only, in our training data only, or in both. The y-axis represents viral sharing link number, scaled to have a mean of 0 and a standard deviation of 1 within each order for clarity. Black points represent means; error bars represent standard errors. Supplementary Figure 5 displays these same data without the within-order scaling.
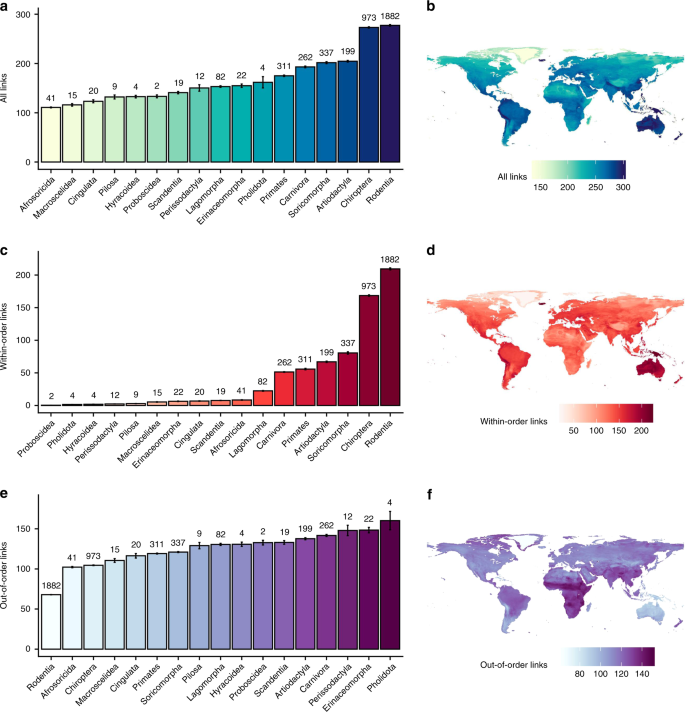
Top row: all viral sharing links; middle row: viral sharing links with species in the same order; bottom row: viral sharing links with species in another order. a, c, e Average species-level viral sharing link numbers for mammalian orders in our dataset. Bars represent means; error bars represent standard errors. b, d, f Geographic distributions of mean viral sharing link numbers. Distributions were derived by summing the viral sharing link numbers of all species inhabiting a 25 km2 grid square and dividing them by the number of species inhabiting the grid square, giving mean degree number at the grid level.
The high predicted centrality of known hosts may be due partly to selective sampling (i.e., viral researchers are more likely to sample common, wide-ranging host species that also share viruses with many other species10,20). This possibility is supported by the increased degree centrality for species that appear in both EID2 and our dataset rather than in only one of the two, as these species are presumably more well-known (Fig. 2c). Similarly, while we believe that our model was successful at accounting for variation in host-level diversity and study effort that influences network topology (see above; Supplementary Fig. 1), there are certain inherent biases in the training data which must be considered when interpreting our findings. Most notably, viral sharing estimates in our dataset may be affected by the fact that zoonotic discovery efforts commonly search limited geographic regions for a specific virus or group of viruses, artificially increasing the likelihood of detecting these viruses in the same region compared to a geographically random sampling regime. Moreover, when a mammal species (e.g., a bat) is found with a focal virus (e.g., an ebolavirus), it is logical for researchers to then investigate similar, closely related species in nearby locales34. These sampling approaches could disproportionately weight the network towards finding phylogeographic effects on viral sharing probability. However, it is highly encouraging that our model predicted patterns in the external EID2 dataset, which was constructed using different data compilation methods but also comprises global data covering several decades of research30. In sum, we believe that our approach is a conservative method for minimising the biases inherent in the data. The knowledge that the observed mammalian virome is biased ultimately calls for more uniform viral sampling across the mammal class and increased coverage of rarely-sampled groups, lending support to ongoing efforts to systematically catalogue mammalian viral diversity3.
Taxonomic and geographic patterns of predicted viral sharing
Our network predicted strong taxonomic patterns in the probability of viral sharing. Looking across mammalian orders, rodents (Rodentia) and bats (Chiroptera) had the most predicted species-level viral links, while carnivores and artiodactyl ungulates had substantially fewer (Fig. 3a). Examining multiple mammalian orders allowed us to partition the predicted sharing network into within- and between-order links to investigate whether certain orders are better-connected to other orders. Indeed, this partitioning revealed differences in taxonomic and geographic patterns of viral sharing. In bats and rodents, large numbers of within-order links are driven by high within-order species diversity (Fig. 3c). Interestingly, when within-order links were ignored, leaving only out-of-order links, rodents and bats were among the least-connected Eutherian orders (Fig. 3e), while even-toed ungulates and carnivores were ranked among the most-connected (Fig. 3e). Taken together, these results imply that while bats and rodents are important in viral sharing networks, their sharing is mainly restricted to other bats and rodents, respectively. This distinction only applied to mean link numbers; when link numbers were summed, rodents and bats remained highly connected regardless of which metric was used, as a result of their species richness (Supplementary Fig. 6).
Previous analyses have demonstrated that both bats and rodents are important for hosting zoonotic viruses, with possible explanations including species-level phenotypic traits such as behaviour5, life history9, or metabolic idiosyncracies35. Our results imply that while both orders potentially host many zoonoses purely as a result of their species richness (Supplementary Fig. 6), the vast majority of their viral sharing occurs within-order even though larger phylogenetic jumps are necessary for human spillover. Intriguingly, recent work has shown that infection of an aggregated phylogenetic selection of hosts is an important contributor to viral zoonotic potential36. Rodents’ and bats’ tendency towards high viral interconnectedness could encourage viruses to achieve such aggregation, leading to opportunities for spillover into humans. In our analysis, both orders’ high centrality emerged purely as a result of their phylogenetic diversity and geographic distributions, rather than from other phenotypic traits. If well-connected species in our network are more likely to maintain a high diversity of viruses (e.g., via multi-host dynamics that help to maintain a threshold population size37), this may contribute to the high viral diversity documented in bats and rodents5. Efforts to prioritise viral sampling regimes should consider biogeography and mammal–mammal interactions in addition to searching for species-level traits associated with high viral diversity.
Encouragingly, our network showed predictable scaling laws similar to those of other known ecological networks38. Viral link numbers in within-order subnetworks (e.g., between different bat species) correlated strongly with species diversity within each order (R2 = ~0.85), following a power law with a Z value of ~0.8 (Supplementary Fig. 7). Similarly, out-of-order links (e.g., between a bat and a rodent) scaled linearly with the product of the species richness of both orders (Supplementary Fig. 8).
To visualise geographic patterns of viral sharing, we projected species-level degree centrality across the species’ ranges, then calculated grid cell-level mean degree centrality (Fig. 3b), as well as summed degree centrality (Supplementary Fig. 6). Average centrality peaked in tropical areas of South and Central America, Sub-Saharan Africa, and Southeast Asia, especially in the Andes and Himalayas (Fig. 3b). These patterns align with previously-reported hotspots of emerging zoonoses and predicted viral diversity5,33 and imply that areas of high biodiversity are centres of viral sharing not just because of the number of overlapping species (i.e., high species richness), but also because more closely related species create a more connected viral sharing network in these areas. This densely-connected network structure and the increased biomass present in the tropics might have synergistic implications for cross-species maintenance and transmission of viral diversity in these areas. The geographic distributions of mean predicted within- and between-order viral links differed notably from the distribution of interspecific links generally: the relative importance of South America and East Asia was higher for within-order links (Fig. 3d), while Sub-Saharan Africa remained a hotspot for out-of-order links (Fig. 3f). Geographic patterns of summed link numbers more closely mirrored underlying host species richness, whether for all links, within-order links, or out-of-order links (Supplementary Fig. 6).
We acknowledge that our phylogeographic model of viral sharing does not account for complex ecological interactions such as coinfection or coevolution, which could impact how patterns of exposure and host susceptibility translate to realised viral diversity. Future investigations could extend our framework to simulate the dynamic co-speciation of mammals and their viruses in order to account for these processes and/or to explicitly investigate how viral sharing connectivity and viral diversity are correlated across mammal species. Our model may also prove useful for building and parameterising much-needed multi-host network models for conservation purposes, particularly where there is scarce prior information on interspecific pathogen sharing37,39.
The network as a predictive tool
Identifying potential hosts for known and novel viruses is an important component of preemptive zoonotic disease surveillance that can speed public health responses. Predictive techniques based on species-level phenotypic and genomic data have been suggested to help prioritise sampling targets6,7,9. To augment these approaches representing a promising methodological advance, the network approach captures the additional mechanistic and ecological underpinnings of viral sharing. We therefore interrogated our predicted viral sharing network to investigate whether it could be used to identify potential hosts of known viruses at the species level.
We investigated the predictive potential of our model by iteratively selecting all but one of the known hosts for a given virus, then using the predicted sharing patterns of the remaining hosts to identify how the focal (removed) host was ranked in terms of its sharing probability (see Methods). Our model showed a surprisingly strong ability to predict observed host species for 250 viruses with at least two known (non-human) mammal hosts. In practical terms, these species-level rankings could set sampling priorities for public health efforts seeking to identify hosts of a novel zoonotic virus, where one or more hosts are already known. Across all 250 viruses, the median ranking of the left-out host was 72 out of a potential 4196 mammals (i.e., in the top 1.7% of potential hosts). To compare this ranking to alternative heuristics, we examined how high the focal host would be ranked using phylogenetic relatedness or spatial overlap values alone (i.e., the most closely-related, followed by the second-most-related, etc.). Using this method, the focal host was ranked, on average, 288th (for phylogeny) or 283rd (for space), identifying the focal host in the top 7% of potential hosts and demonstrating that sampling prioritisation schemes based on our phylogeographic model would require only 1/4 as many sampling targets in order to identify the correct sharing host. Our model therefore represents a substantial improvement over search methods based only on spatial or phylogenetic similarity. Our model performed similarly at identifying focal hosts in the EID2 dataset30: for the 109 viruses in the EID2 dataset with more than one host, the focal host was identified in the top 63 (1.5%) potential hosts. In contrast, ranked spatial overlap predicted the focal host in the top 560 hosts, and phylogenetic relatedness in the top 174.
We observed substantial variation in our model’s ability to predict known hosts among different viruses. For example, the correct host was predicted first in every iteration for seven viruses and in the top 10 hosts for 42 viruses. Results for 128 viruses had the focal host falling within the top 100 guesses, and for only six viruses were the model-based host searches worse than chance (i.e., the focal host ranked lower than 50% of all mammals in terms of sharing probability). We used this measure of viral sharing “predictability” to investigate whether certain viral traits affected the ease with which phylogeography predicted their hosts. Viruses with broad host phylogenetic ranges challenge reservoir prediction efforts since many more species must often be sampled before identifying the correct host(s). To investigate whether the predictive strength of our model was limited for viruses with broad host ranges and/or other viral traits, we fitted a linear mixed model (LMM) which showed a strong negative association between viruses’ known phylogenetic host breadth and the predictability of focal hosts (model R2 = 0.70; host breadth R2 = 0.67; Supplementary Fig. 10). This association demonstrates, unsurprisingly, that predicting the hosts of generalist viruses is intrinsically difficult. This adds a potential limitation to the applicability of our network approach, given that zoonotic viruses commonly exhibit wide host ranges2,5. A family-level random effect accounted for little of the apparent variance in predictability among viral families (Supplementary Fig. 9).
Once viral host range was accounted for, hosts of vector-borne viruses were slightly easier to predict than non-vector-borne viruses (R2 = 0.1; Supplementary Fig. 10)—perhaps because the sharing of vector-borne viruses depends more heavily on host geographic distributions (Supplementary Fig. 3). Despite additional variation in the data, no other viral traits (e.g., RNA vs DNA, segmented vs non-segmented) were important in the LMM. This implies that host phylogeographic traits are a good broad-scale indicator of viral sharing, particularly when ecological specifics of the virus itself are unknown.
Conclusions
In summary, we present a simple, highly interpretable model that predicted a substantial proportion of viral sharing across mammals and is capable of identifying species-level sampling priorities for viral surveillance and discovery. It is worth noting that the analytical framework and validation we describe were conducted on a global scale, while many zoonotic sampling efforts occur on a national or regional scale. Restricting the focal mammals to a regional pool may alter the applicability of our model in certain sampling contexts, and future studies could leverage higher-resolution phylogenetic and geographic data to fine-tune predictions. In particular, the mammalian supertree29 has relatively poor resolution at the species tips such that relatedness estimates based on alternative molecular evidence (e.g., full genome data from hosts) may allow more precise estimates of the phylogenetic relatedness effect on viral sharing. Alternatively, our model could be augmented with additional host, virus, and pairwise traits, using similar pairwise formulations of viral sharing as a response variable. Such model augmentations may better identify ecological specificities that are critical for the transmission of certain viruses, allow for partitions by viral subtypes, and, ultimately, may increase the accuracy of host predictions. By generalising the spatial and phylogenetic processes that drive viral sharing, our model serves as a useful guide for the prioritisation of viral sampling, presenting a baseline for future modelling efforts to compare against and improve upon.
Our ability to model and predict macroecological patterns of viral sharing is important in an era of rapid global change. Under all conceivable global change scenarios, many mammals will shift their geographic ranges, whether of their own volition or through human assistance. Mammalian parasite communities will likely undergo considerable rearrangement as a result, with potentially far-reaching ecological and health consequences40,41,42,43. Our findings suggest that novel species encounters will provide opportunities for interspecific viral transmission, which could be facilitated by even relatively small changes in range overlap. These future cross-species transmission events will have profound implications for conservation and public health, potentially devastating populations of host species without evolved resistance to novel viruses (e.g., red squirrel declines brought about by parapoxvirus infections spread by introduced grey squirrels22) or increasing zoonotic disease risk by introducing viruses to human-adjacent amplifier hosts (e.g., horses increasing the risk of human infection with Hendra virus20). Thus, our global model of mammalian viral sharing provides a crucial complement to ongoing work modelling the spread of hosts, vectors, and their associated diseases as the result of climate change-induced range expansions26,40,43.
Source: Ecology - nature.com

